本文结合R语言,展示了异常检测的案例,主要内容如下:
(1)单变量的异常检测
(2)使用LOF(local outlier factor,局部异常因子)进行异常检测
(3)通过聚类进行异常检测
(4)对时间序列进行异常检测
一、单变量异常检测
本部分展示了一个单变量异常检测的例子,并且演示了如何将这种方法应用在多元数据上。在该例中,单变量异常检测通过boxplot.stats()函数实现,并且返回产生箱线图的统计量。在返回的结果中,有一个部分是out,它结出了异常值的列表。更明确点,它列出了位于极值之外的胡须。参数coef可以控制胡须延伸到箱线图外的远近。在R中,运行?boxplot.stats可获取更详细的信息。
如图呈现了一个箱线图,其中有四个圈是异常值。

如上的单变量异常检测可以用来发现多元数据中的异常值,通过简单搭配的方式。在下例中,我们首先产生一个数据框df,它有两列x和y。之后,异常值分别从x和y检测出来。然后,我们获取两列都是异常值的数据作为异常数据。
在下图中,异常值用红色标记为"+"



类似的,我们也可以将x或y为异常值的数据标记为异常值。下图,异常值用'x'标记为蓝色。

当有三个以上的变量时,最终的异常值需要考虑单变量异常检测结果的多数表决。当选择最佳方式在真实应用中进行搭配时,需要涉及领域知识。
二、使用LOF(local outlier factor,局部异常因子)进行异常检测
LOF(局部异常因子)是用于识别基于密度的局部异常值的算法。使用LOF,一个点的局部密度会与它的邻居进行比较。如果前者明显低于后者(有一个大于1 的LOF值),该点位于一个稀疏区域,对于它的邻居而言,这就表明,该点是一个异常值。LOF的缺点就是它只对数值数据有效。
lofactor()函数使用LOF算法计算局部异常因子,并且它在DMwR和dprep包中是可用的。下面将介绍一个使用LOF进行异常检测的例子,k是用于计算局部异常因子的邻居数量。下图呈现了一个异常值得分的密度图。

接着,我们结合前两个主成份的双标图呈现异常值。

在如上代码中,prcomp()执行了一个主成分分析,并且biplot()使用前两个主成分画出了这些数据。在上图中,x和y轴分别代表第一和第二个主成份,箭头表示了变量,5个异常值用它们的行号标记出来了。
我们也可以如下使用pairsPlot显示异常值,这里的异常值用"+"标记为红色。

Rlof包,对LOF算法的并行实现。它的用法与lofactor()相似,但是lof()有两个附加的特性,即支持k的多元值和距离度量的几种选择。如下是lof()的一个例子。在计算异常值得分后,异常值可以通过选择前几个检测出来。注意,目前包Rlof的版本在MacOS X和Linux环境下工作,但并不在windows环境下工作,因为它要依赖multicore包用于并行计算。


三、通过聚类进行异常检测
另外一种异常检测的方法是聚类。通过把数据聚成类,将那些不属于任务一类的数据作为异常值。比如,使用基于密度的聚类DBSCAN,如果对象在稠密区域紧密相连,它们将被分组到一类。因此,那些不会被分到任何一类的对象就是异常值。
我们也可以使用k-means算法来检测异常。使用k-means算法,数据被分成k组,通过把它们分配到最近的聚类中心。然后,我们能够计算每个对象到聚类中心的距离(或相似性),并且选择最大的距离作为异常值。
如下是一个基于k-means算法在iris数据上实现在异常检测。
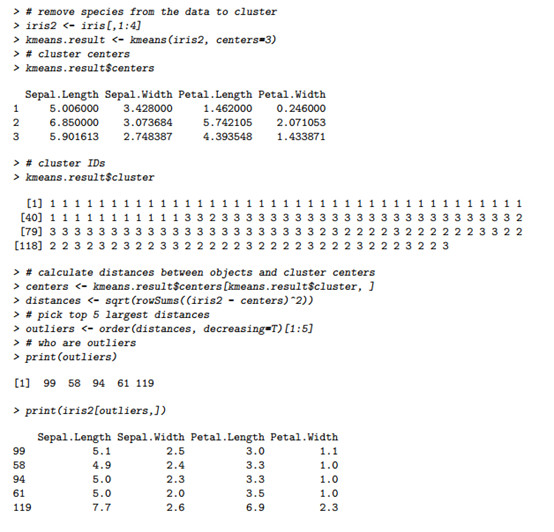

在上图中,聚类中心被标记为星号,异常值标记为'+'
四、对时间序列进行异常检测
本部分讲述一个对时间序列数据进行异常检测的例子。在本例中,时间序列数据首次使用stl()进行稳健回归分解,然后识别异常值。STL的介绍,请访问 http://cs.wellesley.edu/~cs315/Papers/stl%20statistical%20model.pdf.

在上图中,异常值用红色标记为'x'
五、讨论
LOF算法擅长检测局部异常值,但是它只对数值数据有效。Rlof包依赖multicore包,在Windows环境下失效。对于分类数据的一个快速稳定的异常检测的策略是AVF(Attribute Value Frequency)算法。
一些用于异常检测的R包包括:
extremevalues包:单变量异常检测
mvoutlier包:基于稳定方法的多元变量异常检测
outliers包:对异常值进行测验